

The beautiful thing about learning is that nobody can take it away from you. – B.B. King
Moving forward with my #50DaysOfUdacity challenge, today i got to continue with lesson two(Introduction to machine learning) and i was able to complete three sections in lesson two namely :
- Brief history of ML
- The data science process
- Common types of data
As usual, i'll be sharing what i learnt today from these lessons with y'all.
Brief history of ML
Let's take a trip down memory lane and see as ML had evolve with it's impacts over time. Early in the 50's when ML wasn't in the spotlight and only few knew what it was and how to implement it's algorithms, Alan Turing a british logician and computer pioneer designed the turing machine in 1950 bringing about a substantial development and contribution to the field of AI(Artificial intelligence) . In 1945 Turing predicted that computers would one day play very good chess, and just over 50 years later in 1997 Garry Kasparov, the world chess champion was beaten by Deep Blue, a chess computer built by the International Business Machines Corporation (IBM) in a six-game match.
In 2010, Microsoft Kinect a gesture recognition for its Xbox 360 gaming console where people could interact with the computer by their gesture was released. in 2014 Facebook's Deep face which is a facial recognition system was introduced and recently in 2016 Google's Deep mind AlphaGo defeated legendary Lee Sedol the world champion in the game of Go where he lost the tourney 4 games to 1, despite this three years later Deep mind's developers announced that the latest version of AlphaGo defeated the version that beat Sedol 100 games to 0. What's next for machine learning ? the possibilities tend to seem endless...
The data science process
In this section, we'll review the activities that are part of the data science process but before going further what is data science and how is it related to machine learning ?
Data science is a science of extracting knowledge and insights from data in order to make business decisions.
Machine Learning vs Data science
Most folks tend to think ML and Data science means the same, and these terms are mostly used consistently, the boundaries or difference more correctly between ML and Data science is that a ML model is an AI system that learns pattern from data without being explicitly programmed to do so and these ML model run as a piece of software either embedded in websites such as Netflix or via mobile applications. In contrast, data science is the process of extracting insights from datasets in order to make meaningful and important business decisions. To explain furthermore, a ML project often results in a piece of software that can be deployed and executed while a data science project would often consist of a slide deck(power point presentation) describing or summarizing conclusions for executives to take proper business actions or for a product team to decide how to improve their software product or a website.
The data science process
Big data has become part of the lexicon of organizations worldwide, as more and more organizations look to leverage data to drive informed business decisions. With this evolution in business decision-making, the amount of raw data collected, along with the number and diversity of data sources, is growing at an astounding rate. This data presents enormous potential.
Raw data, however, is often noisy and unreliable and may contain missing values and outliers. Using such data for modeling can produce misleading results. For the data scientist, the ability to combine large, disparate data sets into a format more appropriate for analysis is an increasingly crucial skill.
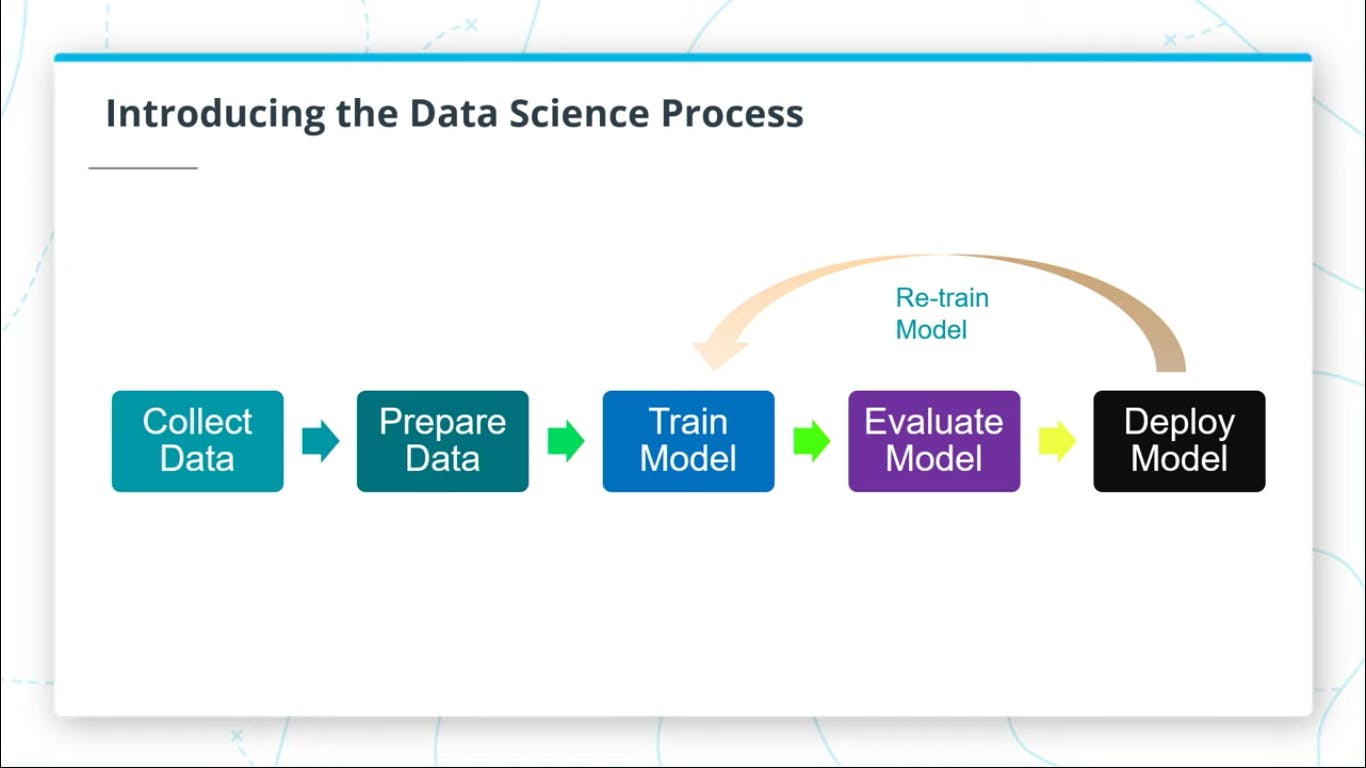
The data science process typically starts with collecting and preparing the data before moving on to training, evaluating, and deploying a model. Let's have a look.
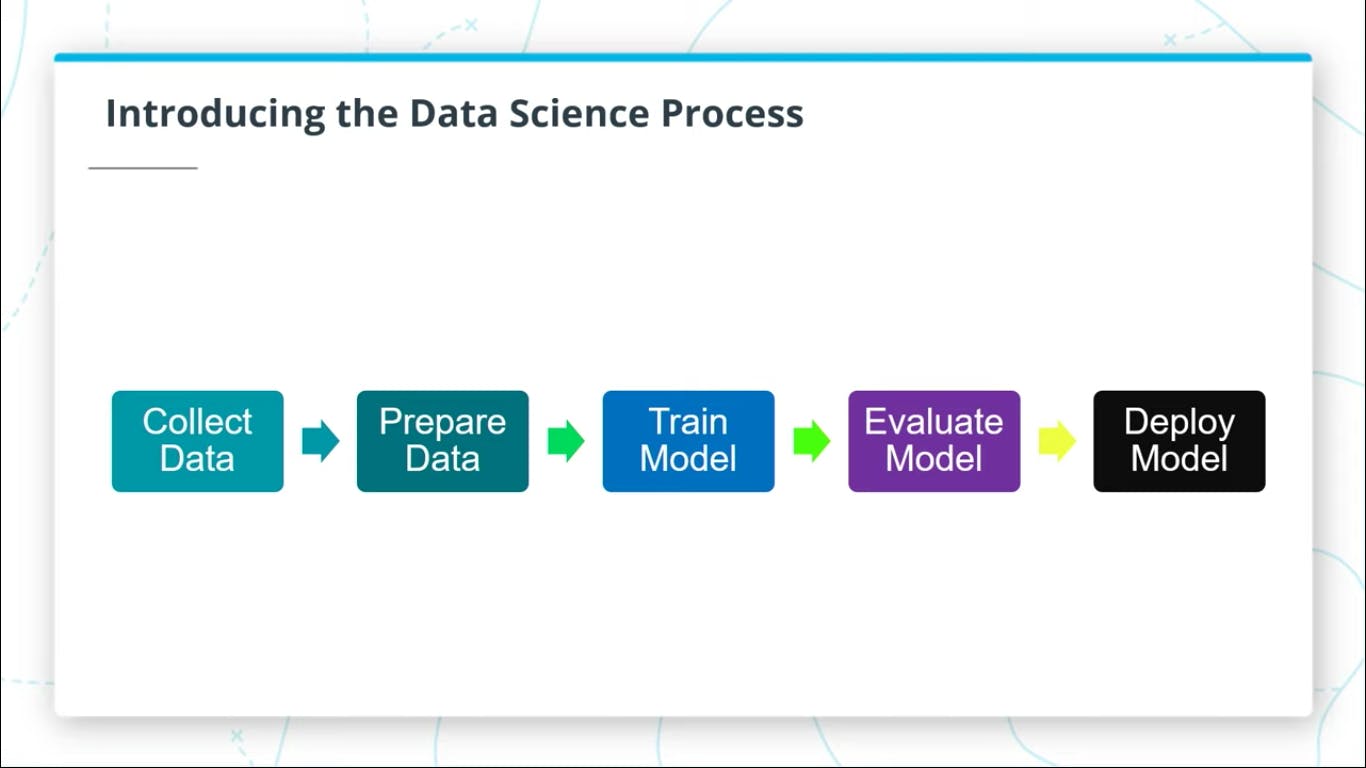
The last step in the process is retraining the model, as time goes on and more data are being generated, it is required to re train our model with new data, this process is an iterative step simply because with time, fresh data would be acquired and our model needs to be retrained in order to achieve optimal performance.
Common Types Of Data
What is more, all data in machine learning eventually ends up being numerical, regardless of whether it is numerical in its original form, so it can be processed by machine learning algorithms.
For example, we may want to use gender information in the dataset to predict if an individual has heart disease. Before we can use this information with a machine learning algorithm, we need to transfer male vs. female into numbers, for instance, 1 means a person is male and 2 means a person is female, so it can be processed. Note here that the value 1 or 2 does not carry any meaning.
Another example would be using pictures uploaded by customers to identify if they are satisfied with the service. Pictures are not initially in numerical form but they will need to be transformed into RGB values, a set of numerical values ranging from 0 to 255, to be processed.
Further Reading
Here's a link to an article to learn more about AI, ML and Deep learning click here