

The more that you read, the more things you will know. The more that you learn, the more places you’ll go. – Dr. Seus
Hi there, i am here again today on another episode of Machine Learning with Microsoft Azure foundations course and today i was able to cover few sections of lesson two.
Common types of data

Numerical These are either integer or floats just like we have in traditional programming examples are sales prices, identifiers of objects etc.
Time-series Time-series are a set of data points, each of which represents the value of the same variable at different times, normally at uniform intervals. Simply put, they are a series of numerical values that can be ordered e.g real time stock prices
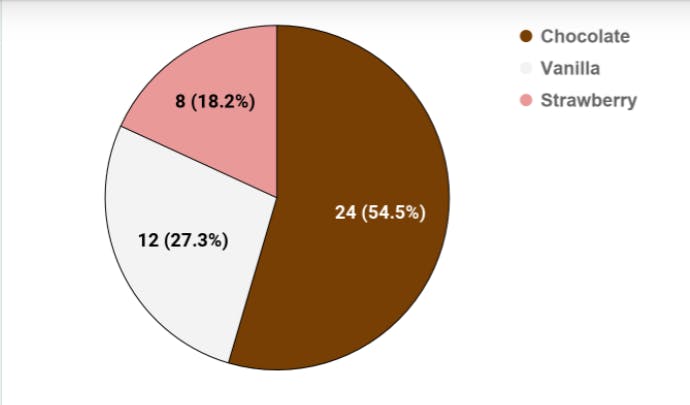
Categorical This includes discrete data in categories or groups. An example is a chart displayed below
Text These includes sentences or words. The major challenge faced with such type of data includes transforming it to a numeric equivalent form that is much more appropriate for a ML algorithm. There are various approaches to tackle this challenges which would be discussed later as time goes by.
Image Examples of these are images, screenshots, short clip videos or even a full stream of video. Images are also not initially in numerical form but they will need to be transformed into RGB values, a set of numerical values ranging from 0 to 255, in order to be processed by a ML algorithm.
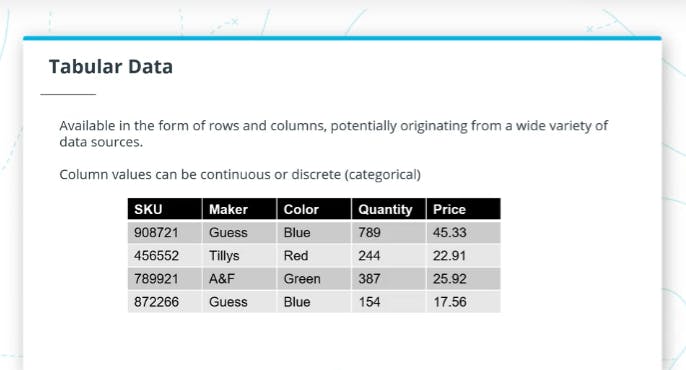
Tabular Data This is the most common type of data you'll come across when dealing with ML. Tabular data are data arranged in a data table, they are always in form of rows and columns which is essentially the same format as you work with when you look at data in a spreadsheet. Here's an example of tabular data showing some different clothing products and their properties, where a row describes a single case, item or entity and a column describes a property that the items or entities the table can have. The column with non numeric values such as maker and color in the image below would eventually be represented as numbers, also i the case of continuous data such as quantity and price ,best practices states that we scale the input data for optimal model performance.
It is important to know that in machine learning we ultimately always work with numbers or specifically vectors.
A vector is simply an array of numbers, such as (1, 2, 3)—or a nested array that contains other arrays of numbers, such as (1, 2, (1, 2, 3)).
Vectors are used heavily in machine learning, For now, the main points you need to be aware of are that:
- All non-numerical data types (such as images, text, and categories) must eventually be represented as numbers
- In machine learning, the numerical representation will be in the form of an array of numbers—that is, a vector
Scaling Data
Scaling data means transforming it so that the values fit within some range or scale, such as 0–100 or 0–1. There are a number of reasons why it is a good idea to scale your data before feeding it into a machine learning algorithm.
Let's consider an example. Imagine you have an image represented as a set of RGB values ranging from 0 to 255. We can scale the range of the values from 0–255 down to a range of 0–1. This scaling process will not affect the algorithm output since every value is scaled in the same way. But it can speed up the training process, because now the algorithm only needs to handle numbers less than or equal to 1.
Two common approaches to scaling data include standardization and normalization.

Standardization
Standardization rescales data so that it has a mean of 0 and a standard deviation of 1.
The formula for this is:
(𝑥 − 𝜇)/𝜎
We subtract the mean (𝜇) from each value (x) and then divide by the standard deviation (𝜎).
Normalization
Normalization rescales the data into the range [0, 1].
The formula for this is:
(𝑥 −𝑥𝑚𝑖𝑛)/(𝑥𝑚𝑎𝑥 −𝑥𝑚𝑖𝑛)
Okay folks, that was all for today, see you all tomorrow.
#StaySafe
#KeepLearning
#50DaysOfUdacity